Hallo wereld
Dit keer ga ik jullie een spoedcursus aanbieden in statistiek. In dit bericht zal het tempo wat hoger ligger dan normaal. Wil je een Dataridder worden dan is het echter van belang dat je een beetje werkt aan je conditie!
Op Wikipedia wordt statistiek gedefinieerd als de wetenschap, methodiek en de techniek van het verzamelen, bewerken, interpreteren en presenteren van gegevens. Dat is nogal een mondvol, maar statistiek is in principe niets anders dan de wiskundige theorie achter Data Science.
Wil je meer leren over Data Science dan is het dus belangrijk ook statistiek te leren. Bovendien zal het je helpen mijn toekomstige berichten beter te begrijpen.
Oké, klaar voor de start?

Af!
Hoofdgebieden
In de statistiek zijn er twee hoofdgebieden, de beschrijvende en de inductieve statistiek. Bij de beschrijvende statistiek houdt men zich bezig met de gegevens van een bepaalde populatie, ofwel verzameling van objecten. Hierbij gaat het in tegenstelling tot bij de inductieve statistiek om de gehele populatie, waarbij een steekproef genomen wordt. Dat wil zeggen, er wordt (willekeurig) een deelverzameling uit de totale populatie genomen om informatie over deze populatie te vinden. Dit is noodzakelijk wanneer de gehele populatie te groot is of om andere redenen onmogelijk of onwenselijk is om te onderzoeken.
Gegevens
Ook kan men onderscheid maken tussen numerieke en categorische gegevens. Binnen categorische gegevens kan men weer verder onderscheid maken tussen ordinale (geordende) en nominale (ongeordende) kenmerken. Een voorbeeld voor een ordinaal kenmerk is bijvoorbeeld leeftijdsgroep (kind, volwassene, bejaarde), en een voorbeeld voor een nominaal kenmerk is kleur (rood, groen, blauw). Numerieke gegevens kunnen worden opgedeeld in discrete en continue waarden. Discrete waarden nemen alleen bepaalde waarden aan met constante intervallen ertussen in, bijvoorbeeld aantallen. Continue waarden kunnen alle waarden (binnen een bepaald interval) aannemen op de numerieke schaal, zoals bijvoorbeeld gewicht of tijd.
Visualisatie
Om categorische data te visualiseren kunnen we onder andere gebruik maken van kolomdiagrammen, staafdiagrammen of taartdiagrammen. We visualiseren dan het aantal of percentage van objecten dat van een bepaalde categorie is. Om numerieke data te visualiseren kunnen we onder andere gebruik maken van tijdgrafieken, histogrammen, stamdiagrammen en spreidingsdiagrammen.
Kolomdiagrammen en staafdiagrammen zijn heel simpel. Er wordt in zo’n diagram gewoon een aantal staven weergegeven die het aantal (of percentage) van objecten van een bepaalde categorie representeren. In het geval kolomdiagrammen zijn die staven verticaal en in het geval van staafdiagrammen horizontaal. Taartdiagrammen zijn ook niet al te ingewikkeld. In plaats van staven hebben we hier te maken met cirkelsegmenten die de percentages representeren van de categorieën. Waarschijnlijk zul je deze grafieken allemaal al eerder gezien hebben.
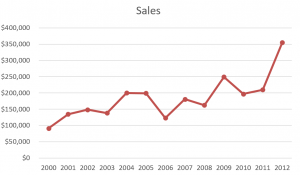
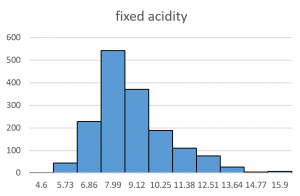
Tijdgrafieken zul je ook vast al kennen. We hebben hier dan een lijn door een aantal punten met op de horizontale as de tijd en op de verticale as de afhankelijke variabele. Histogrammen en stamdiagrammen zijn visuele representaties van de zogenaamde frequentietabel. In een frequentietabel word de verdeling van een verzameling numerieke waarden weergegeven. Er wordt hierbij aangegeven hoe veel van de getallen binnen de gekozen intervallen voorkomen. In een histogram wordt daar dan simpelweg een kolomdiagram van gemaakt, in een stamplot worden deze gegevens in getalvorm weergegeven. In de stam, de getallen links van de lijn, staan dan de eerste getallen van de waardes. De bladeren zijn de overige getallen van de gesorteerde waardes in de verzameling.

Halverwege, ga zo door!
Numerieke presentatie
Naast visuele manieren voor het presenteren van data zijn er ook numerieke methodes. De belangrijkste eigenschappen van verzamelingen binnen de statistiek zijn centrummaten en spreidingsmaten.
De belangrijkste centrummaten zijn het gemiddelde, de mediaan en de modus. Het gemiddelde is de som van de waardes gedeeld door het aantal. De mediaan is de waarde die in het midden van de gesorteerde reeks ligt. In het geval van een even aantal is hij gelijk aan het gemiddelde van de twee middelste getallen. De modus is het getal dat het meeste voorkomt.
De belangrijkste spreidingsmaten zijn de standaardafwijking en de variatie. Deze getallen geven aan hoe ver de getallen over het algemeen van het gemiddelde afliggen. De standaardafwijking, ook wel standaarddeviatie genoemd, rekent men uit met de volgende formule.

De variatie is simpelweg het kwadraat van deze standaarddeviatie.
Percentielen en doosdiagrammen
Ook kunnen we de data representeren met percentielen en de vijf-getallensamenvatting. Percentielen geven aan voor welk getal een bepaald percentage van de getallen onder dit getal vallen. Een goed voorbeeld hiervan is het 50ste percentiel, ook wel bekend als de mediaan. Voor dit getal vallen dus 50 procent van de getallen onder dit getal (en 50 procent erboven). Als we dan het minimum, 25ste percentiel, 50ste percentiel, 75ste percentiel en maximum nemen hebben we de vijf-getallensamenvatting. Deze kunnen we visualiseren aan de hand van een doosdiagram. Hierbij wordt de data binnen de 25ste en 75ste percentielen weergegeven als een rechthoek (doos) en de minima en maxima met zogenaamde snorharen.

Eventjes doorzetten nog!
Correlatie
Correlatie is de statistische samenhang tussen twee variabelen. We kunnen bijvoorbeeld waarnemen dat er een positief verband bestaat tussen het aantal uur dat een student studeert en het cijfer dat hij haalt. Het gedrag van zo’n correlatie wordt in het geval van een lineair verband uitgedrukt door middel van de correlatiecoëfficiënt. Deze kan varieren van -1 tot +1. Bij -1 is er een perfect negatief verband, bij +1 een perfect positief verband. Dit zegt echter niets over de helling van dit lineaire verband, alleen hoe goed de punten binnen een verzameling op een dergelijke lijn vallen. Lineaire regressie is het proces waarbij de lijn die zo’n correlatie zo goed mogelijk beschrijft berekend wordt.
Experimentatie
Ook kunnen we niet automatisch aannemen dat bij zo’n verband een variabele de oorzaak is en de andere het gevolg. Vaak zijn er een hele hoop andere factoren die op de achtergrond meespelen. Om met zekerheid te kunnen vast stellen of een correlatie een causaal (oorzaak-gevolg) verband beschrijft is het noodzakelijk om een goed opgezet (statistisch) experiment uit te voeren. Hierbij wordt dan een aantal objecten aan een bepaalde behandeling blootgesteld en daarna wordt het effect van die behandeling geobserveerd. Bijvoorbeeld het geven van een bepaald medicijn aan een muis en observeren of het effectief is of niet. Op deze manier kunnen we dan uitspraken doen over oorzaak en gevolg, mits zo’n experiment goed is opgezet en de resultaten op de juiste wijze worden geïnterpreteerd. Bij deze experimenten is het in geval van steekproeven (vrijwel altijd het geval) zowel van belang om objecten willekeurig te selecteren voor behandelingen en zoveel mogelijk objecten te bestuderen, zodat resultaten representatief zijn voor de gehele populatie.
Finish!

En nu ben je een expert in statistiek!
Nou ja, niet echt natuurlijk. Er is nog veel meer te leren. Op het moment ben ik dat zelf aan het doen met het gratis e-book ThinkStats en met af en toe een video uit de playlist Crash Course Statistics op Youtube. Dus als je meer wilt leren kun je daar kijken, of misschien in de onderstaande bronnen. Maar als je deze spoedcursus hebt volgehouden dan ben je al een heel eind op weg! Dat is alles voor nu.
Tot de volgende keer!
Bronnen:
- Simple Learning Pro – Statistics 1 Playlist
- Statistiek – Wikipedia
- Statistiek op de TU Eindhoven
- Meer Wikipedia