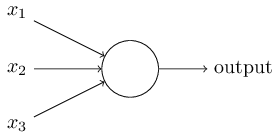
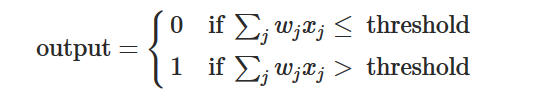Sommigen zijn overtuigd van wel.
Anderen zien AI gewoon als een overtuigende autocomplete.
En eigenlijk is die onenigheid zo vreemd nog niet.
Taalmodellen kunnen namelijk zowel verrassend slim als verrassend idioot zijn.
Maar hoe komt dat nou?
Om dat uit te leggen, eerst een verhaaltje.
De magische papegaai
Er was eens een magiër met een liefde voor papegaaien.
Hoewel hij het leuk vond om met zijn vogels te babbelen, was hij toch een beetje teleurgesteld over de diepgang van de gesprekken.
Daarom bedacht hij een spreuk, en probeerde hem uit op een van zijn papegaaien.
De vogel ontwikkelde hierdoor een absurd scherp gehoor.
Jarenlang kon hij meeluisteren naar alle gesprekken in het koninkrijk.
Gesprekken van:
* sluwe generaals,
* bedreven dokters,
* toegewijde priesters,
* en gewoon, het ijverige werkvolk.
En toen gebeurde er iets bijzonders.
De wijze vogel
De papegaai begon langzamerhand steeds meer patronen te ontdekken in wat hij hoorde.
Daardoor ontwikkelde hij bijzondere gaven.
Hij kon:
* overtuigend advies geven,
* prachtige verhalen vertellen,
* gezellig over koetjes en kalfjes meepraten,
* en complexe vragen beantwoorden die zelfs de magiër ver boven het hoofd gingen.
Al snel was het hele koninkrijk er druk van in de weer.
De papegaai was niet alleen behulpzaam, hij leek ook écht te begrijpen waar hij het over had.
Velen begonnen zelfs te geloven dat de papegaai een soort van orakel was!
Met een grote ceremonie werd de papegaai naar een pronkstuk in de troonzaal verplaatst, om daar mensen uit het hele koninkrijk te hulp te staan.
Maar langzamerhand begonnen er barstjes te ontstaan in het beeld van de wijze vogel…
De hongerige magiër
Terwijl dit zich allemaal afspeelde was er nog een magiër aan het experimenteren.
Jarenlang was deze zonder eten opgesloten in een geluidsdichte kerker.
Om niet om te komen van de honger bedacht hij een spreuk om brood tevoorschijn te toveren.
Een spreuk die nog niemand hem had horen uitspreken.
Op een dag ontsnapte hij en hoorde over de beroemde papegaai.
Hoewel hij best tevreden was over zijn spreuk, hoopte hij dat de wijze vogel deze verder kon verbeteren.
Dus vroeg hij die:
“Mijn spreuk maakt prachtig brood, maar ik krijg er nooit kaas bij. Heb je ideeën?”
De papegaai keek hem vragend aan.
“Welke spreuk?…”
Na een wat ongemakkelijke stilte draaide de magiër teleurgesteld om, nam een hap uit zijn brood en ging op zoek naar de keuken voor wat kaas.
De hoopvolle ridder
Niet lang daarna verscheen er een ridder in de troonzaal die gewond geraakt was tijdens een gruwelijke drakenaanval.
De arme ridder had daarbij zijn stem verloren, en beheerste alleen gebarentaal.
Met trillende handen probeerde hij de papegaai duidelijk te maken wat hij wilde.
Kon de wijze vogel hem misschien helpen zijn stem terug te krijgen?
De papegaai keek hem alleen verward aan.
Ook de ridder ging teleurgesteld naar huis.
De wijze vogel had immers nog nooit gebarentaal geleerd.
Het ondeugende kind
Tot slot kwam er een ondeugend jongetje bij de papegaai.
Met een grijns legde hij een pinda op de grond, en plaatste een glazen koepel eroverheen.
De papegaai sprong van zijn pronkstuk en probeerde met grote frustratie de pinda te bereiken.
Steeds opnieuw tikte hij tegen het glas, maar tevergeefs.
De hele troonzaal barstte uit in het lachen!
De wijze vogel kon wellicht meepraten over praktisch alle onderwerpen in het koninkrijk.
Maar hij wist nog steeds niet hoe hij een glazen stolp op moest tillen.

Wat heeft dit nou met AI te maken?
Stiekem best veel.
Taalmodellen zoals ChatGPT werken namelijk op een manier die opvallend veel lijkt op die papegaai. Ze leren niet van de echte wereld. Ze leren van tekst.
Een hele hoop tekst.
En daarvan leren ze verrassend veel.
Model van de werkelijkheid
Wanneer mensen praten over dingen zoals wetenschap, wiskunde, en hun gevoelens over wiskunde, dan zit daar een menselijk wereldmodel achter.
Een taalmodel leert indirect van dat model.
En het resultaat daarvan lijkt verrassend veel op begrip.
Maar dat begrip is toch net wat anders.
Model van taal
Mensen bouwen hun wereldmodel meestal op vanuit ervaring.
Ze maken dingen mee, denken over dingen na (soms, maar ook niet altijd), en op basis daarvan bouwen ze een model van de realiteit op.
Vervolgens leggen ze dat model vast in tekst.
En een taalmodel leert van die tekst om indrukwekkend goed tekst te kunnen voorspellen.
Nou ja, natuurlijk is het net iets ingewikkelder (vandaar ook al die andere Dataridder artikelen), maar in principe komt het daar allemaal op neer.
Maar begrijpt AI ons nou of niet?
Goede vraag.
Het lijkt er dus op dat AI vooral begrijpt hoe tekst werkt. Niet zozeer wat die tekst nou echt betekent.
Maar dat betekent niet dat AI geen kennis heeft, niets begrijpt of geen nieuwe ideeën kan vormen.
Integendeel, het kan verbanden leggen waar mensen zelf nooit aan dachten, complexe problemen oplossen door het voorspellen van redeneringen, en zo’n beetje overal over meepraten.
Maar uiteindelijk blijft AI afhankelijk van tekst om te kunnen doen wat het doet.
En dat geeft mogelijkheden, maar heeft ook beperkingen.
Taalmodellen zijn daardoor verrassend slim, maar soms ook verrassend idioot.
En we vragen ons vaak af of ze ons nou echt begrijpen, en of ze nou echt slim zijn.
Maar misschien is de interessante vraag nou juist:
“Hoe kunnen AI-modellen zoveel zonder ons echt te begrijpen?”

Als je het antwoord op die vraag wil weten is het misschien geen slecht idee om ook wat van die andere Dataridder artikelen te lezen. Bijvoorbeeld: